Improved Scene Identification and Object Detection on Egocentric Vision of Daily Activities
Introduction
We study some computer vision techniques that help to exploit inherent constraints of first-person camera video of individuals performing daily activities.

Figure a) contains an image taken in a kitchen. Figure b) shows a list of possible objects that could be detected. From the list, only the coffeemaker makes sense in the observed context.
In the case of activities of daily living, the actions typically are performed in common places associated with human residences such as bathroom, corridor, patio, kitchen, among others, which will be referred as the scenes. Then, we are interested in the frame level scene identification problem, where the goal is to find the correct scene identity for all the frames of the egocentric video.
We note that temporal constraints can be exploited to improve frame level scene identification performance. The location where an activity is performed remains consistent for several frames until the user changes his / her current location. Given a frame, several trained scene classifiers are evaluated and a decision about the identity is taken based on the classification scores. However, the scores obtained for individual frames can lead to wrong scene identification since these scores are agnostic with respect to the temporal constraints associated with egocentric vision.
We are also interested in the problem of improving the detection of objects. Consider, for example, Figure 1(a) which shows a picture from a kitchen. Figure 1(b) shows a list of possible objects that could be interesting to detect. It is obvious for humans that some types of objects are unlikely to be found in the observed scene, while a coffeemaker is an object that most likely can be found in this type of scene. This observation is used as a constraint in our problem formulation to improve the quality of object detectors. We concentrate on Activities of Daily Living (ADL), where most of the first person activities are performed in few prototypical scenes that are common to all the actors.
Method
a) Improving Scene Identification using a Conditional Random Field (CRF) formulation
We are dealing with first-person camera videos where the scene identity of a frame is influenced by the identities of previous frames. It is evident that a person requires some time to move from one scene to another, therefore, if a person is known to be in a particular scene, it is very likely that the individual will remain on the same stage during some additional frames.We use a Conditional Random Field (CRF) formulation to model the temporal constraint of scene identities associated with first-person videos. The goal is to find the scene labels y =y1 , y2 , · · · , yN for a video sequence with N frames, that best fit the scores of the scene classifiers while enforcing the temporal constraint.
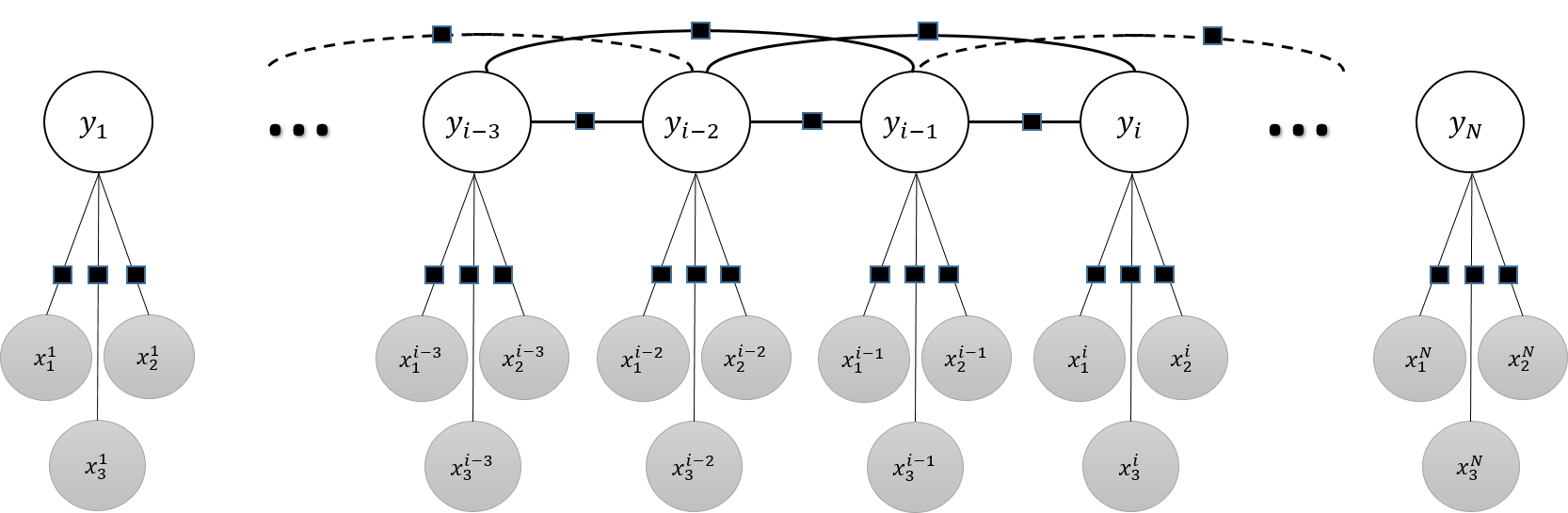
Example of a graphical model representing temporal dependencies for scene labeling in a first-person camera video. A total of r = 2 previous observations and three possible scene identities are represented in the figure. The figure shows the observations (scene scoring) as shadowed nodes x and label assignments as white nodes y. Final experiments in were performed with r = 7.
The energy function to minimize can be represented as
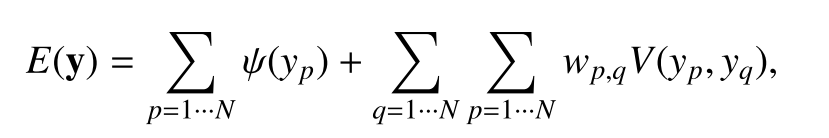
b) Improving object detection
A microwave is commonly found in the kitchen but is very unusual in other locations such as bedroom, bathroom or a laundry room. Consequently, in cases where it is possible to obtain information about the identity of the scene of the current frame, we could re-score the results of the object detector to penalize detections in scenes that typically do not contain the object that we are looking for. Overall, it is possible to increase the performance of the detector by incorporating the information about the particular type of the scene for the frame that is being tested.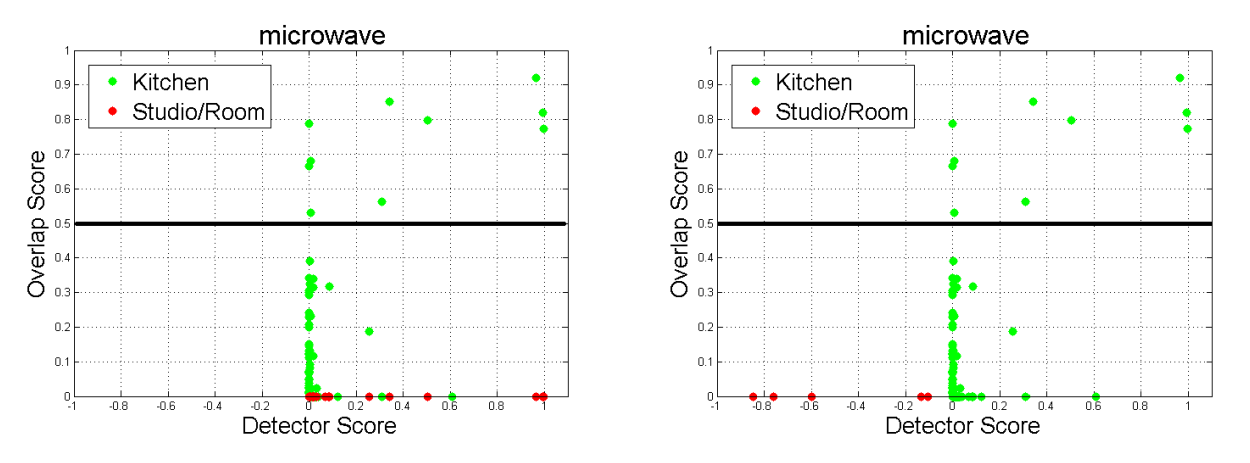
Figures are generated from microwave detector, and show the detection score versus ground-truth match score. Figure a) shows the detections for the kitchen in green and the results for a bedroom in red. Figure b) shows a re-scoring that improves the object detection.
From the figure, it is clear that many valid detections (i.e., overlap score (Area Overlap / Area Total) is over 0.5) can be found in the kitchen scenes. The figure also shows that there is not a single valid microwave detection in bedroom scenes for the training dataset, which is consistent with our common sense understanding.
If we select a threshold for the object detection score that captures most of the valid detections in the kitchen, then such a threshold produces lots of false microwave detections in the bedroom scene; but if we set up a high threshold for microwave detection (in order to avoid adding invalid detection of the bedroom scenes), then a lot of correct detections from the kitchen will be ignored. Figure (b) shows a possible re–scoring for the object detection scores based on the scene identity that deals with the fact that microwaves rarely appear in a bedroom. As can be appreciated from the figure, we have performed a simple shifting of the detection scores appearing in bedroom scenes. As a result, the detections from the bedroom scenes do not add any false positives which allows improving the results of object detection.
Two algorithms are presented for re-scoring in the paper. A greedy algorithm and a Support Vector Regression (SVR) Algorithm. Details of the greedy algorithm can be found at [1].
The SVR algorithm is a re-scoring function as a regression. The problem of regression is equivalent to finding a function which approximately maps from an input domain to the real numbers based on a training sample. Our goal is to map the object detection score to a new score value considering the scene identity. Then, the input data must encode the current scene identity and also include the detection score. The scene identity is encoded as one-hot vector of scene identities i.e. a vector with dimension equal to the number of scenes, with an entry equal to one in the dimension representing the actual scene identity, and zeroes in all the others dimensions. Hence, the input data x is represented by the concatenation of the one-hot scene identity vector and the detection score of the candidate bounding box.
The output data yi is a real that contains the target detection scores. With yi having any one of these possible values:
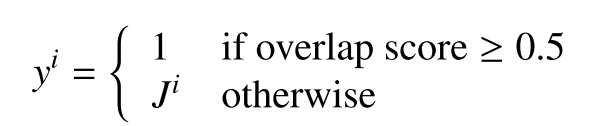
where J represents the overlap score of the candidate detection.
A different regressor is trained for every type of object in the dataset. During testing, the detection score and the output of the scene classifiers are used to encode the input vector. The regression output of the regressor associated to the type of object is used as the new score for the bounding box.
c) Improving Object Detection Without Scene Identity Labeling.
Figure depicts the proposed framework.
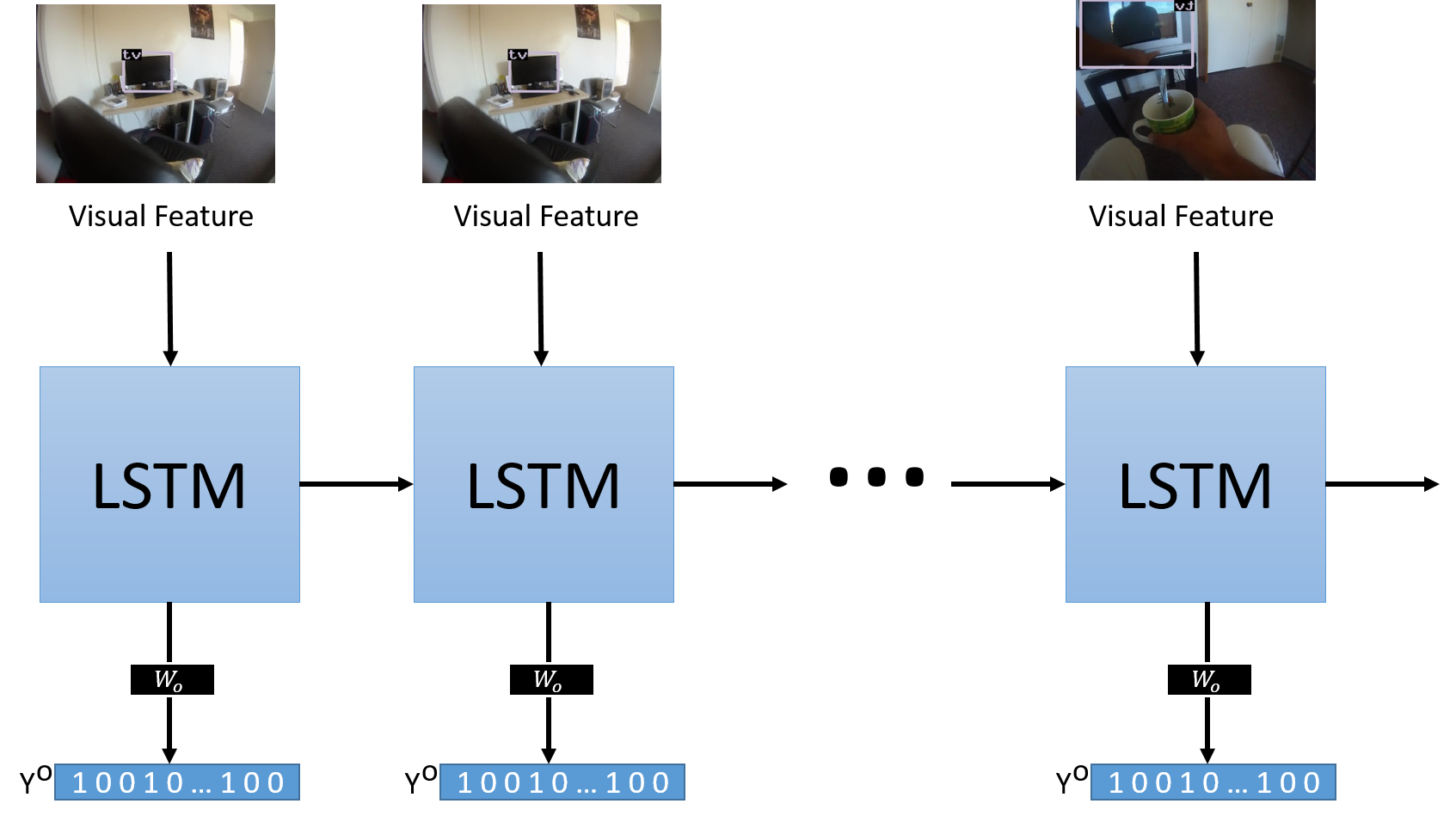
framework to obtain the most likely objects from scene descriptor in a frame sequence. Visual features are used as inputs, while the target vector Y encodes the presence or absence of an object class in the frame.
Every frame is preprocessed to obtain a visual image descriptor which feeds the Long Short-Term Memory (LSTM) network. The system is trained to produce the correct answer to the question: which objects are visible in the image? The answer to the question is encoded also as a vector Yo. The vector Yo has non-zero entries at the positions that indicate the indexes of existing objects in the frame. In training time, we use the information of every frame to fill out the vector Yo, and the image descriptor X.
Results
Scene Identification
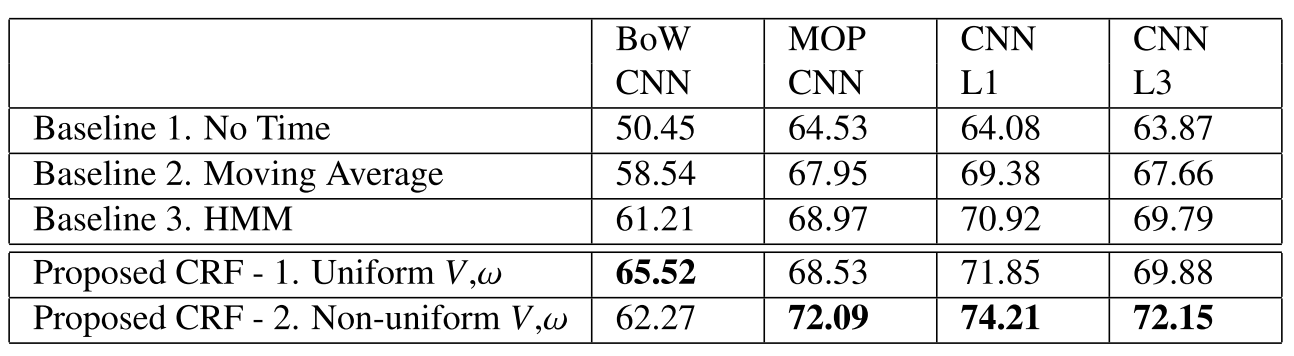
Results for four variants of scene detectors are showed in the table.
Baseline methods for dealing with temporal are:
No time: Using frame by frame results.
Moving average: Using an average filter to smooth temporally.
HMM: Use a Hidden Markov model to model labels over time.
A uniform CRF refers to the case where the last seven frames and that any change of label is penalized equally. A non-uniform CRF referes to the case where a gaussian function is used to express higher influence of the closest previous frames, and changes on labels are penalized according to the changes on the training data.
Improving object detection
Results are presented for DPM detector and for a Fast RCNN object detector fine-tunned on ADL dataset.

A example of re-scoring for a DPM detector.
The results for the DPM detector and Fast-RCNN detector and their improvements are showed in the next tables.
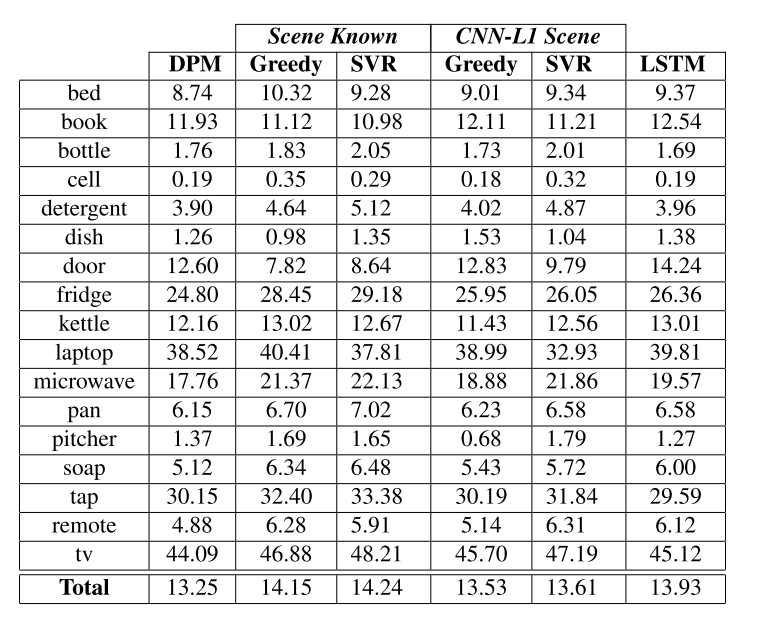
Results for re-scoring of the DPM detector.
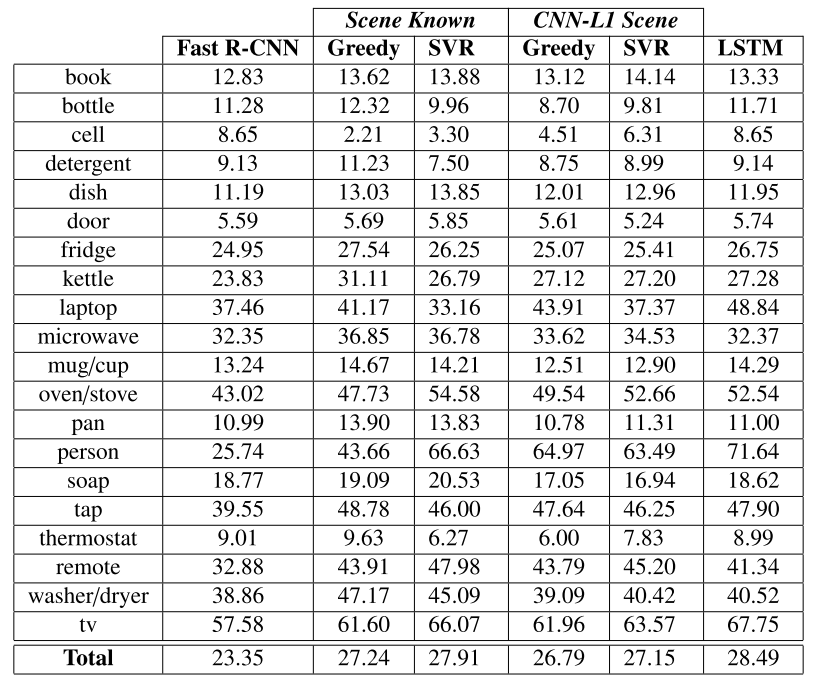
Results for re-scoring of the Fast RCNN detector.
Related Publication
[1] Gonzalo Vaca-Castano, Samarjit Das, and Joao P. Sousa, Improving egocentric vision of daily activities , IEEE International Conference on Image Processing (ICIP), 2015.
[2] Gonzalo Vaca-Castano, Samarjit Das, Joao P. Sousa, Niels D. Lobo, and Mubarak Shah Improved Scene Identification and Object Detection on Egocentric Vision of Daily Activities , Computer Vision and Image Understanding (CVIU), 2016. 10.1016/j.cviu.2016.10.016