Reinforcement Learning (RL) has the ability to learn in an unknown domain
without prior knowledge. RL generally has three main
components: states, actions and reinforcement. The states can be physical
locations, attributes, or any concept that can be encapsulated as a distinct
entity. Each state includes a list of actions that cause a transition from the
current state to some other state. Actions are chosen based on reinforcement
values for that action in a given state. The total combination of a given
action for every state is called a policy. Based on theory, there exists an
optimum policy for which every action for every state is the best.
The learning paradigm chosen for the ReinforcementAgent was Temporal
Difference (TD) learning. This approach uses a table of state action pairs and
their corresponding reward. If an action leads to a good result, but this is
not detected until several steps later, that good result will immediately
propagate back to the initial action and therefore favor it in the future. The
following formula was used in the ReinforcementAgent implementation.
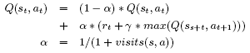
Where α is related to the number of times that the state action pair has
been visited, γ is a user defined value between 0 and 1, Q(s,a) and
r(s,a) is the value and reward for current state action pair respectively.
|
|
The action set for the ReinforcementAgent is defined by 20 movement
actions. Actions for eat, attack and flee is also included in the action set.
The state set consist of various energy level thresholds, possible actions to
take in each game round and on the objects and their directions as seen in the
agent's sensors. In total there are 117760 state action pairs. Reinforcement is
applied using direct stimuli from the environment. Reinforcement is calculated
using the difference in energy from previous turn and current turn. Negative
reinforcement is imposed when the agent fail to perform some action or when the
agent performs to many consecutive actions of equal type. In similar manner,
positive reinforcements is given when an agent successfully performs some
action.
The temporal depth level, or action chain depth, was empirically set to 5. This
value was chosen for several reasons. First, it needed to be greater than four
since the method of successive actions that returned to the previous state was
penalized in this system. Second, four moves and eat was the number of actions
required at a maximum to eat most food in the local map sensor range. Finally,
it was experimentally determined to be a good balance of delaying reward that
seemed to make sane decisions that were not too local and much longer the
global reward seemed to not converge easily.
|
